blockr.io Showcase: File I/O Blocks
blockr-io-showcase.RmdIntroduction
blockr.io provides unified file I/O blocks for reading and writing data in blockr pipelines. The read block handles loading data from multiple sources and formats with a smart, adaptive interface. The write block enables exporting data to various file formats, with support for browser downloads or filesystem output. Together, these blocks make it easy to build complete data workflows from input to output.
Read Block
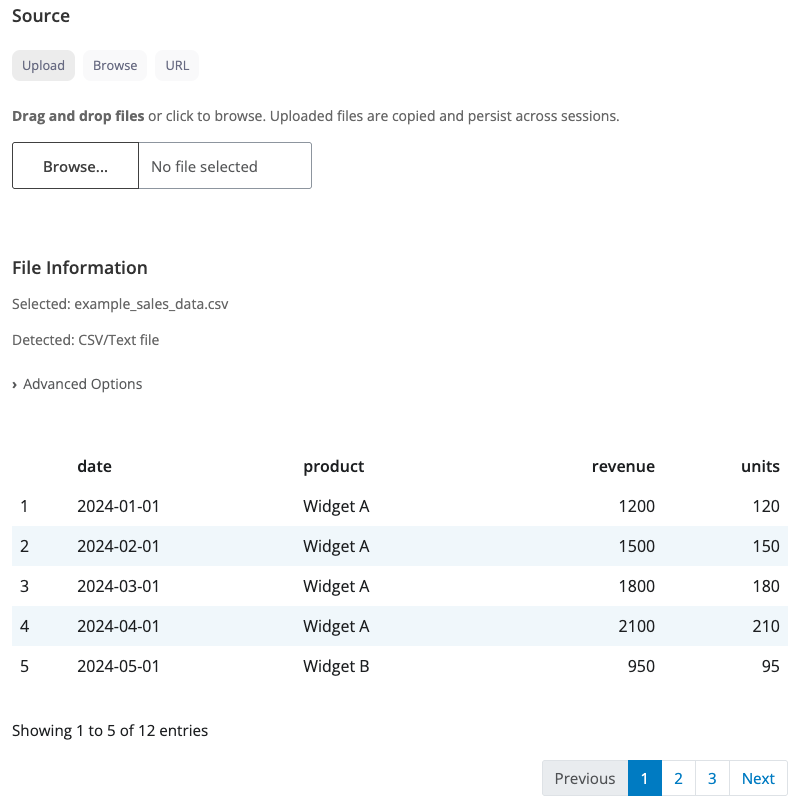
The read block is a versatile data loading block that automatically adapts its interface based on the file type you’re working with. It combines three different file source modes (upload, browse, URL) with format-specific options for CSV, Excel, and other file types.
Three Ways to Load Data
Upload Mode: Drag and drop files or click to browse from your computer. Uploaded files are stored persistently, so they remain available across sessions. This is perfect for interactive data analysis where you want to upload a dataset once and keep working with it.
Browse Mode: Navigate your file system using an interactive file browser. Select files from configured folder paths. The block reads directly from the original file location without copying.
URL Mode: Download data directly from a web URL. Simply paste a URL pointing to a CSV, Excel, or other supported file format. The data is downloaded fresh when the session starts.
Smart Interface
The block detects your file type and shows relevant options:
CSV/TSV files display options for delimiter (comma, semicolon, tab), quote character, encoding, row skipping, and whether the first row contains column names. This gives you full control over how delimited text files are parsed.
Excel files show dropdown menus for sheet selection, cell range specification (like “A1:C100”), row skipping, and column name options. You can target specific sheets and ranges within your Excel workbooks.
Other formats (Parquet, Feather, SPSS, Stata, SAS, JSON, XML, etc.) are handled automatically with minimal configuration. The block uses the appropriate reader based on file extension.
Working with Multiple Files
When you select multiple files, the block provides combination strategies:
- Auto: Automatically stacks files vertically if they have the same columns, otherwise uses just the first file
- Row bind: Stack files vertically (requires files to have the same columns)
- Column bind: Place files side-by-side (requires files to have the same number of rows)
- First only: Use only the first file, ignore the others
This makes it easy to load and combine related datasets in one step.
Read block interface showing CSV options
Supported File Formats
The block supports a wide range of file formats:
Text formats: CSV, TSV, TXT, fixed-width files
Spreadsheets: Excel (.xlsx, .xls), OpenDocument Spreadsheet (.ods)
Statistical software: SPSS (.sav), Stata (.dta), SAS (.sas7bdat, .xpt)
Columnar formats: Parquet, Feather, Arrow IPC
Web formats: JSON, XML, HTML
R formats: RDS, RData
Database formats: DBF, SQLite
Write Block
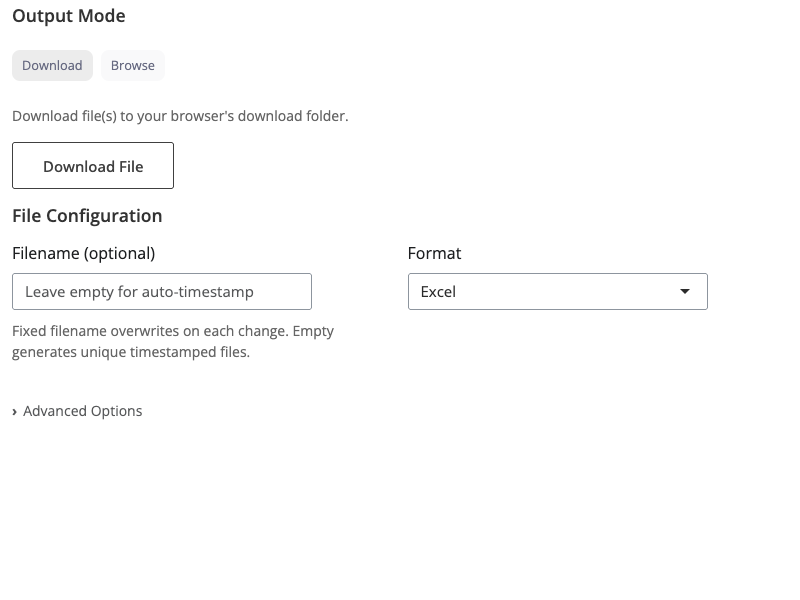
The write block is a versatile data export block that accepts one or more dataframe inputs and outputs files in various formats. It provides flexible options for file naming, output location, and format-specific parameters.
Two Output Modes
Download Mode: The block triggers a browser download, saving the file to your downloads folder. This is the recommended mode for beginners and for exporting analysis results. Files are generated on-demand when you click the download button.
Browse Mode: Write files directly to the server filesystem. Use the directory browser to select where files should be saved. Files are written immediately when upstream data changes, making this ideal for automated pipelines.
Filename Behavior
Fixed filename: Specify a filename (without extension) to create reproducible output. The block always writes to the same path, overwriting the file when upstream data changes. Perfect for automated workflows where you want consistent file paths.
Auto-timestamped: Leave the filename empty to
generate unique timestamped files (e.g.,
data_20250127_143022.csv). This preserves history and
prevents accidental overwrites, making it the safe default behavior.
Multiple Input Handling
The write block accepts multiple dataframe inputs, similar to how you might combine datasets. The output format depends on the file type:
Excel format: Multiple inputs become sheets in a single Excel workbook. Sheet names are derived from input names (e.g., “sales_data”, “inventory”).
CSV/Arrow formats: Multiple inputs are bundled into a ZIP archive. Each dataframe is saved as a separate file using the input names.
Single input: Outputs a single file in the specified format.
Supported Output Formats
- CSV: Comma-separated values with configurable delimiter, quotes, and NA handling
- Excel: .xlsx workbooks with support for multiple sheets
- Parquet: Efficient columnar storage format
- Feather: Fast binary format for data frames
Format-specific options (like CSV delimiter or quote character) can
be configured through the args parameter.
Write block interface showing download mode
Building Complete Pipelines
The read and write blocks work seamlessly with other blockr blocks to create end-to-end data workflows. Load data with the read block, transform it with processing blocks, visualize results, and export with the write block - all without writing code.
For example, you could build a pipeline that: 1. Loads sales data from a CSV file (read block) 2. Filters to show only high-revenue transactions (filter block) 3. Aggregates by product category (summarize block) 4. Creates a visualization (plot block) 5. Exports the processed data to Excel (write block)
Just connect the blocks together to create powerful, reproducible data workflows!